
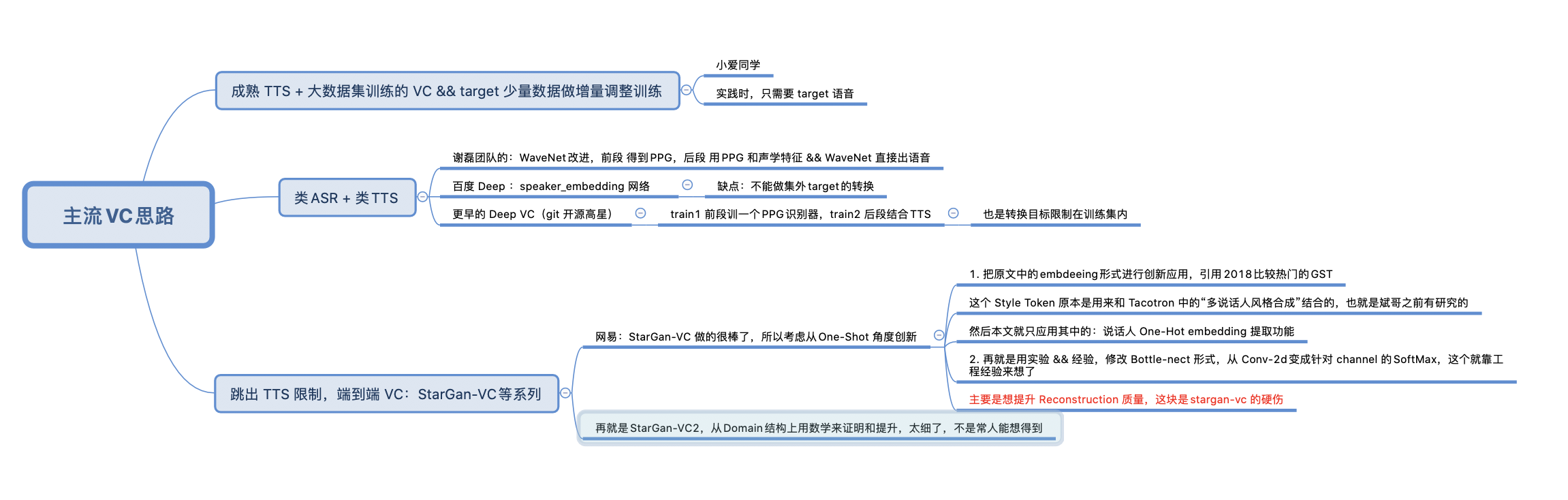
解决的问题:
- 在原本的StarGan-VC中,实现了“未知speaker:source/target 都未知”的转换。称作“One-Shot”
- 其他文章其实也有做过类似功能:基于“超大数据集的 VC 模型”做自适应adaption调整:比如之前谢磊团队那篇 对WaveNet的改进模型,在处理未知说话人时,采用的是 额外20到50条数据的进一步收敛;
采用的主要方法:
- 把说话人信息看作 embedding。
- 但是不同于原本 StarGan-VC 代码实现中(非官方)用 One-Hot来做embedding。
- 也不是用的后来咱们讨论中,改用 embedding_lookup()的方式(虽然已经比One-Hot concate 方式要好很多了)
- 而是采用2018年google的一篇文章,提取embedding的单独网络;(Global Style Token (GST)),用这个网络提取出来的embedding信息,可以表征说话人身份信息。
- 具体细节接下来说:

有价值的细节:
- 这个GST 训练时,先有一堆说话人,每个人有很多数据(1⃣️);
- 然后这个网络的功能就是:能把一个新来的 集合外数据(人/内容),扔进去,照样得到一个 speaker_embedding 信息;
- 这个embedding信息怎么来的呢?原来是由模型(1⃣️)训练集中的说话人embedding 融合出来的;所以最终的效果上,会是:新说话人声音特征,由训练集说话人特征组合而成;
- 这个GST当中, speaker ID 实现上,同样采用 one-hot 形式。
以上三点,其实都只是前人的工作,本文拿来创新性应用。
- 本文的细节创新:
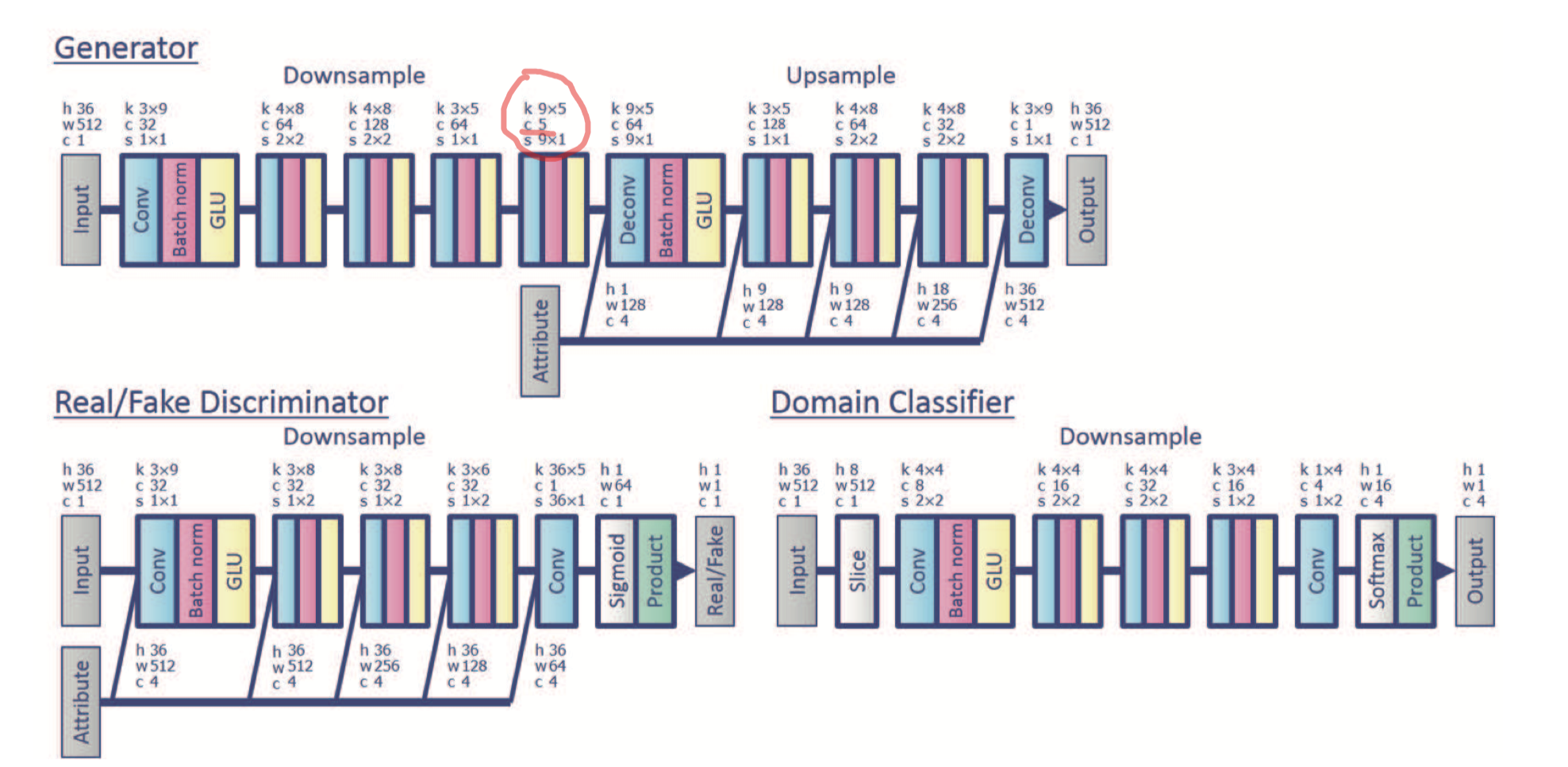
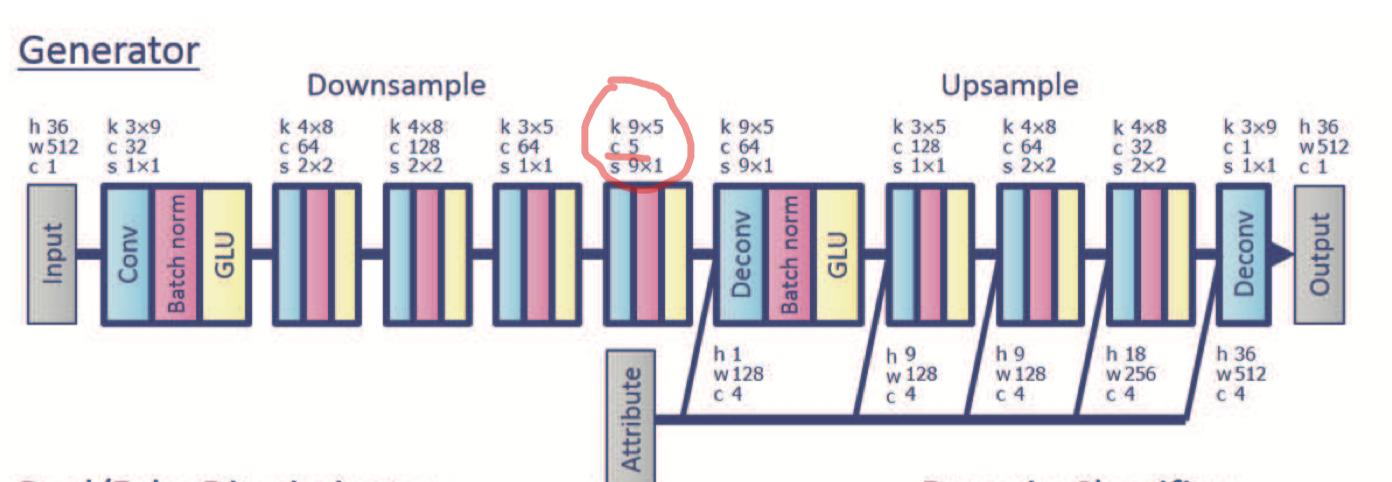
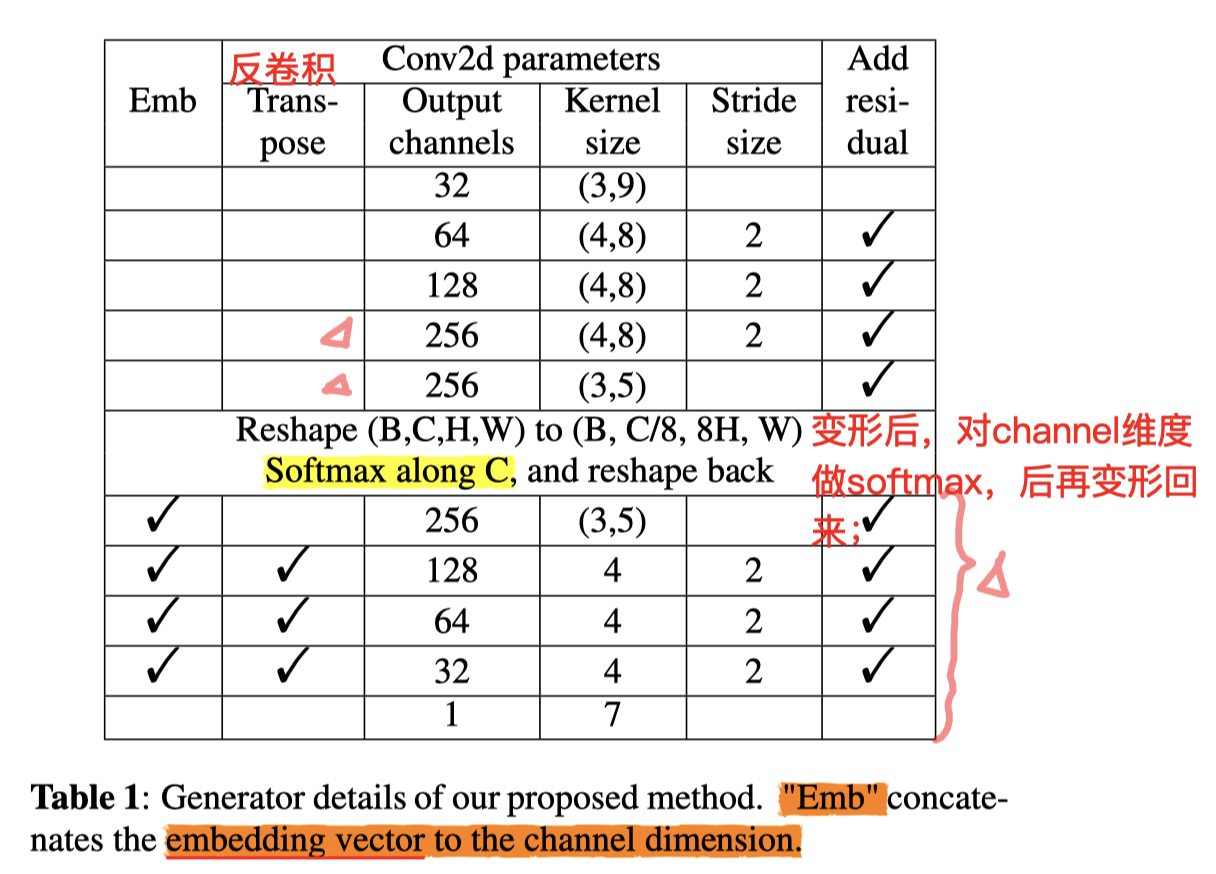
- 原本的 StarGan-VC 中,在Generator部分 的BottelNect部分,采用正常的 【Conv,Norm,GLU】结构,其中的Conv采用 5 个channel;
- 本文作者实验证明,这个 5 channel 太小了,影响了 reconstruction 音频质量;
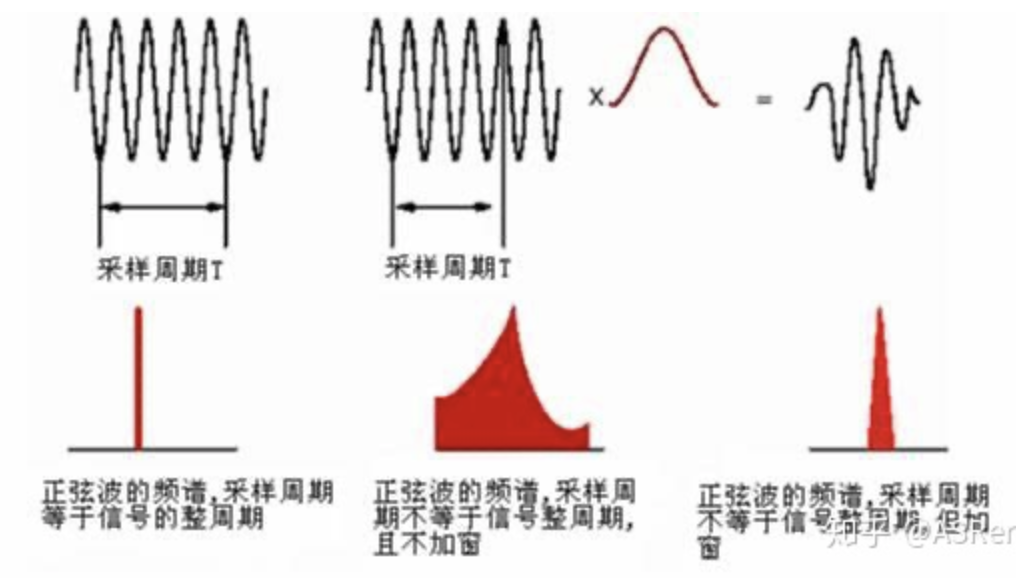
- 但是尝试放大这个channel数,会发现有“信息泄露:information leakage”,有点像信号处理中的“频率泄漏:frequency leak”(后者采用加窗的方式规避这个问题);
- 所谓的泄漏,就是出现了无关的信息:Generator 没能把source中的身份信息过滤干净,最后的声音四不像;(频率泄漏则是,在没加窗函数之前,做FFT会出现 本没有的 频率)
- 最后的效果上:
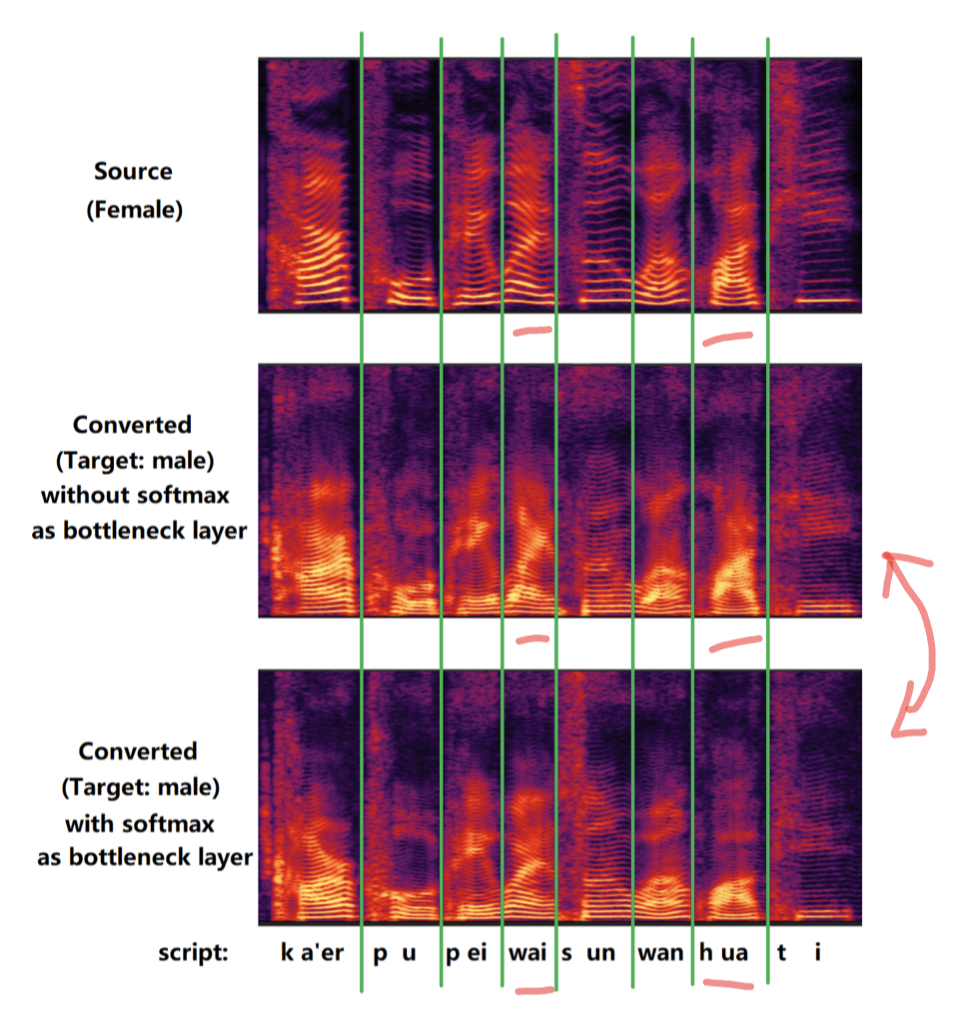
- 作者说,用了这种方式(SoftMax 代替 conv-2d 做 BottleNeck),在转换结果上,共振峰频率(frequencies of formants)会低一点:显示在能量图上,就是高频部分(上面)颜色会浅一点。
- 🌟疑问点:这个 共振峰频率 低一点,能说明什么????这样就能说明 说话内容信息泄漏会少一点吗?没搞懂;
5. 另一个操作改进点:
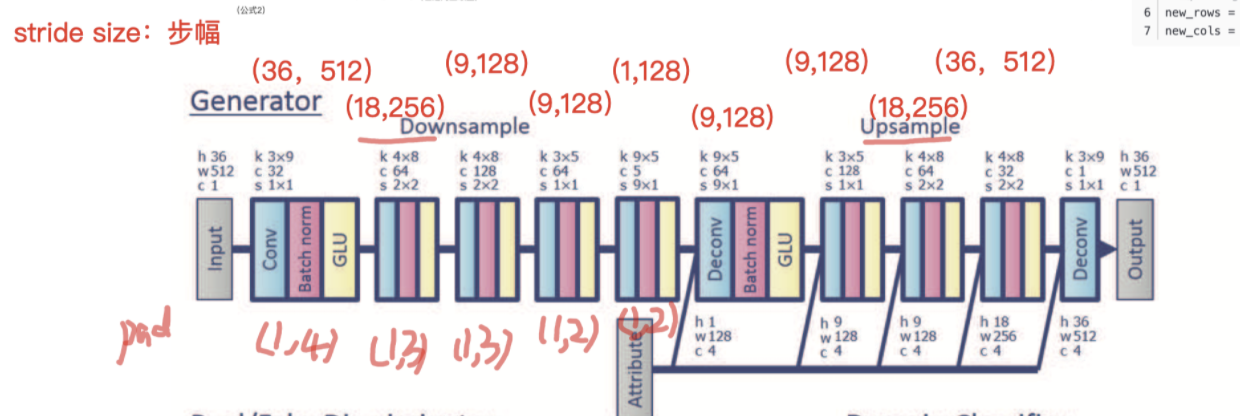
在Generator的修改上如图:
对比原型:
小细节:

偶数:同时更新 D && G
奇数:只更新 D
特征选用上:由实验经验,由36维 MFCC 改为用 96维 sp 谱包络(96-bin Mel spectral envelope)
(这个和合成的应用上也有呼应, Mel 的训练合成,比MFCC reconstrruction 效果要好,更深原理 模糊)
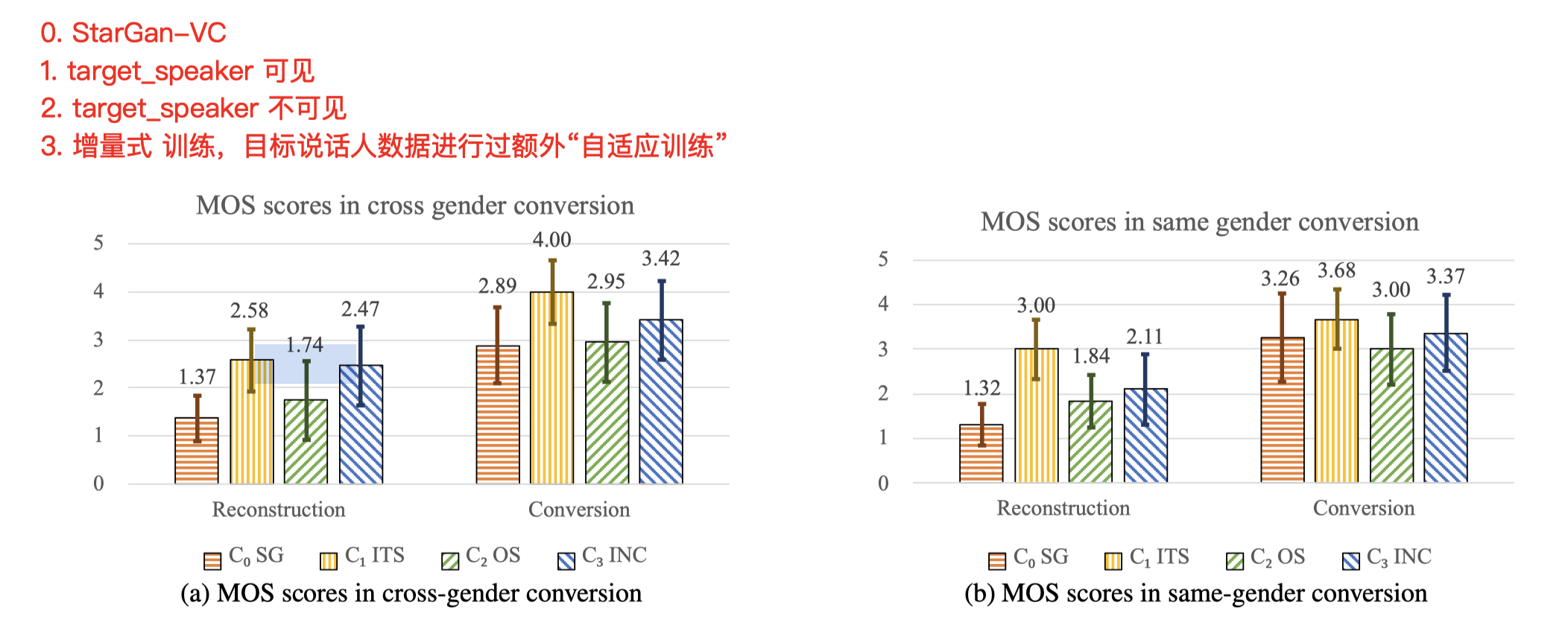
6. 结果上:
其实就是 VC 领域两个主观评价指标:Reconstruction 质量 和 Conversion 质量。
- 这份Demo里,Reconstruction 的效果也不怎么好,在Conversion 转换效果上还凑合;这个和StarGan-VC 差不多;
- Reconstruction 上,target 已知或 “增量式训练”过,数据效果上,提升不少;Conversion 效果也大差不差;
7. VC改进思路小结:
- 在想能否写WorkShop论文
- 不知还有什么可改进的点,咱们可以接上WaveNet后端,类似谢磊上篇用的;
- 然后重构损失上,模型结构学习一下网易这篇。
- embedding 上,为的是实现 one-shot,再考虑是否有其他方法;