1018组会
VQVC 简析
- 《ONE-SHOT VOICE CONVERSION BY VECTOR QUANTIZATION》
- https://ericwudayi.github.io/VQVC-DEMO/

- 《VQVC+: One-Shot Voice Conversion by Vector Quantization and U-Net architecture》

1. 特点
- 模型结构:AE 类型,U-Net 框架
- 常见 VC 特征解纠缠思路:The disentangle capability is achieved by vector quantization (VQ), adversarial training, or instance normalization (IN)
- VQ
- 对抗
- IN
- VQVC:对 隐变量 进行 量化
2. 相关
(一)直接转换语音,不需要单独 “特征解纠缠”
- CycleGAN && StarGAN 专注于解决 “多对多问题”
- BLOW:基于Flow的方式:直接对 波形 进行转换,而不用转换成 语音特征
(二) speaker && linguistic 解耦
- AutoVC—— AE 结构,通过控制 隐变量 尺寸(layer dimension)来实现解纠缠
- IN 法

- VQVC
3. 加入 U-Net 的原因:
- 以上这些 特征解纠缠 的思路可行,但是由于这些额外限制,会使得重构音质受损
- U-Net 的重构能力超级强,所以本身是没法做 VC 的,因为她 解纠缠 能力不好
- 本文尝试 结合 U-Net 的强大重构能力,以及 VQ 的 特征解耦能力,使得转换的语音,在相似度提高的同时,解决流畅度问题;
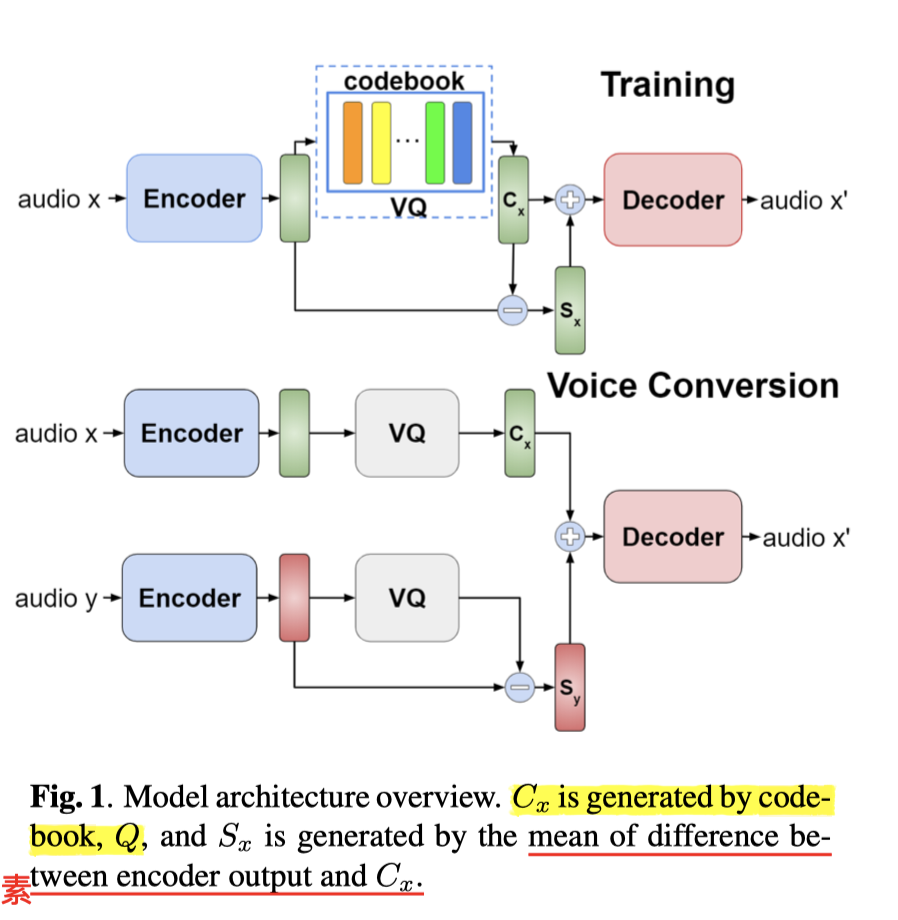
4. VQVC 思路:
- 内容:离散码
- 说话人信息:连续语音信号 - 离散码
- 先做 Encode 得到隐变量 Z;
- 再对这个隐变量做 量化,(结合 codebook ),提取出 内容向量 C(content embedding)——不同说话人,说同样一句话,得到的向量趋于相似向量值;
- 将 Z 和 C 做量化减法,得到 Speaker Embedding——S
内容:离散码
说话人信息:连续语音信号-离散码
- Codebook 本身是可训练的

公式(1):
x(带帽)表示的是 语音 x 中的一个小片段;
argmin 函数:求取 使得函数 y = f(x) 取得最小值的 x 值集合
将 Encode 之后的 隐变量 z,拿来和 Codebook 中的向量 求取差值最小项(欧式距离)
最后的 $C_x$ 是将上述 x^ 做一个整体的 concate 得到的
公式(2):
结合(VQVC+)的部分公式 来看:
- $E_t$ 表示的是,在所有 T 帧上,求取 Z 和 C 的期望值 s,最后将 s 重复 T 次,以此表征 speaker embedding;
- 重复 T 次是为了让 s 的尺寸 和 C 一样,并方便后续操作
公式(3):

- 第一个损失: 重构损失
公式(4)、(5):

- 第二个损失:隐变量损失 L(latent)
- 目的是更好地从 隐变量Z 中提取 Content Embedding,来代表整个语音片段的内容部分
- 🌟值得一提的是:为了让 C 更好地表征内容,在这个环节中,Codebook不做更新:防止网络为了缩小 Loss,而把 Codebook 往 说话人信息方向靠,使得提取出来的 Content Embedding 含有 Spealer 信息;
公式(5):
- 两个 Loss 的叠加
关于 IN:
- 本图来自(VQVC+):
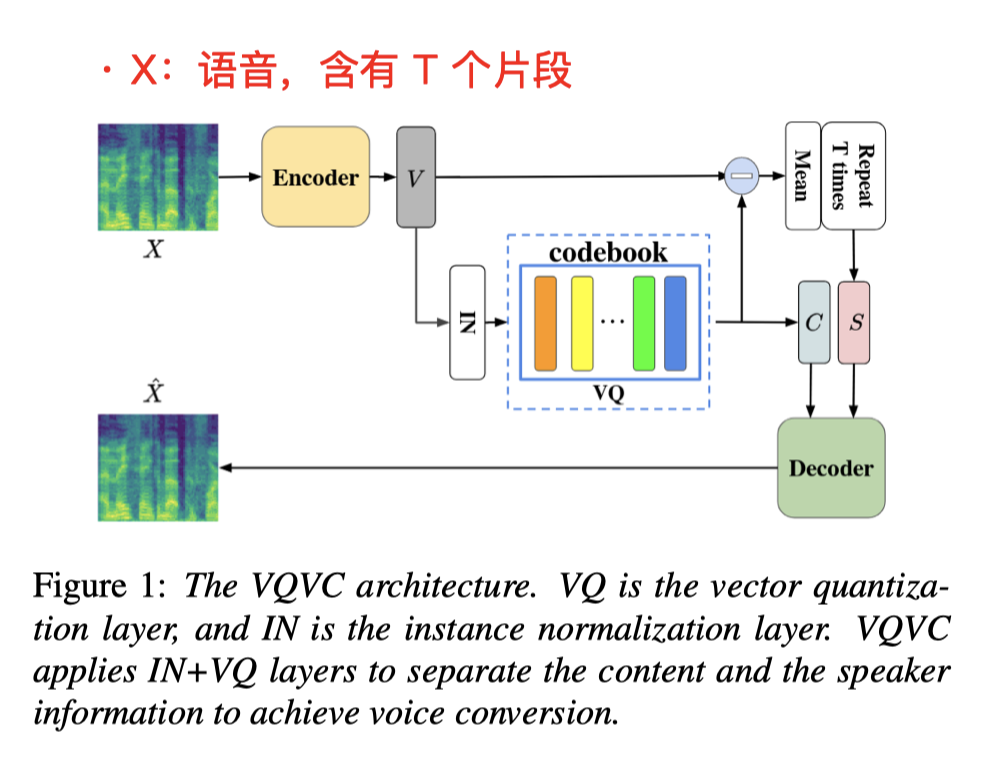
- 在 Encode 得到隐变量 z 之后,在进一步提取 content embedding 之前,需要先做一次 IN(Instant Norm)
- IN 本身也被其他论文证明,具有
- 特征解耦 的功效(这里 IN 是必须操作)
- 这样能预先一步过滤 说话人信息
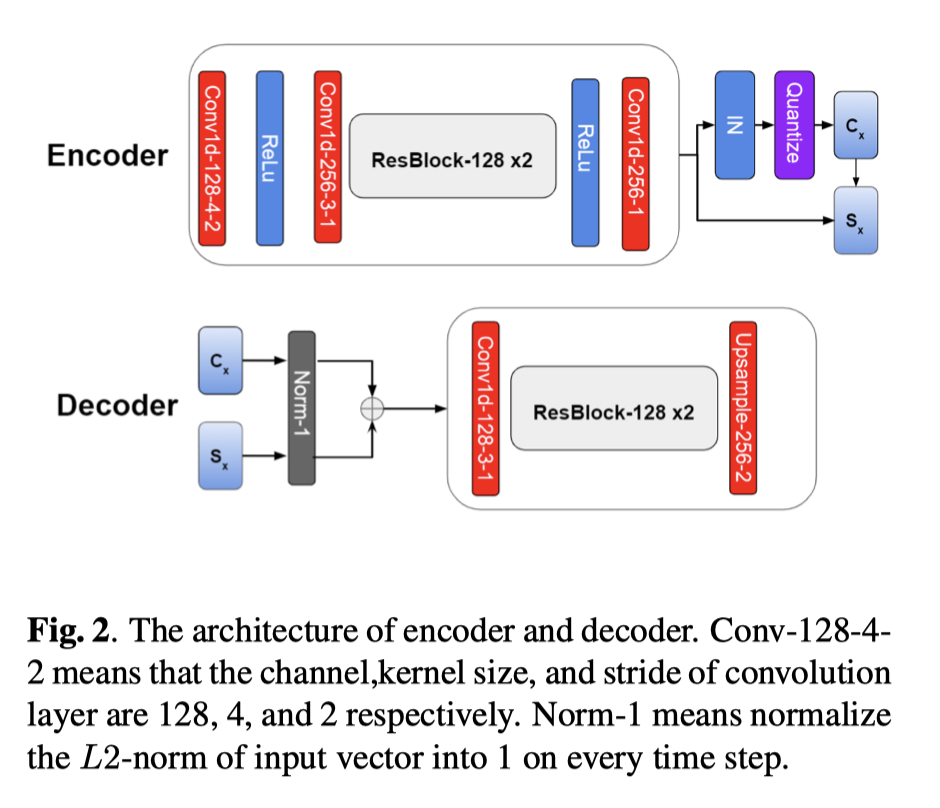
一些特征处理细节:
- n_mels = 160
- GriffinLim
- 24K
- 一些额外的规范化normalize 处理:
- 减去均值,除以均方差,处理到【0,1】


结果:
- 消融实验
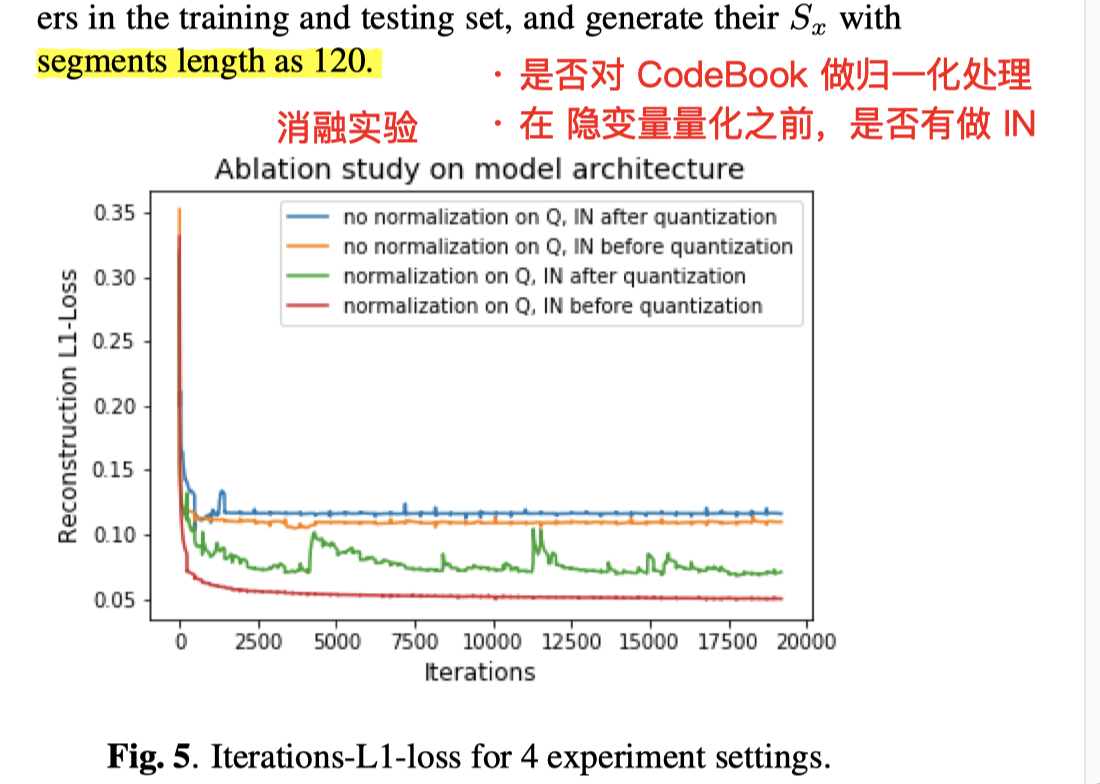
- ABX 实验
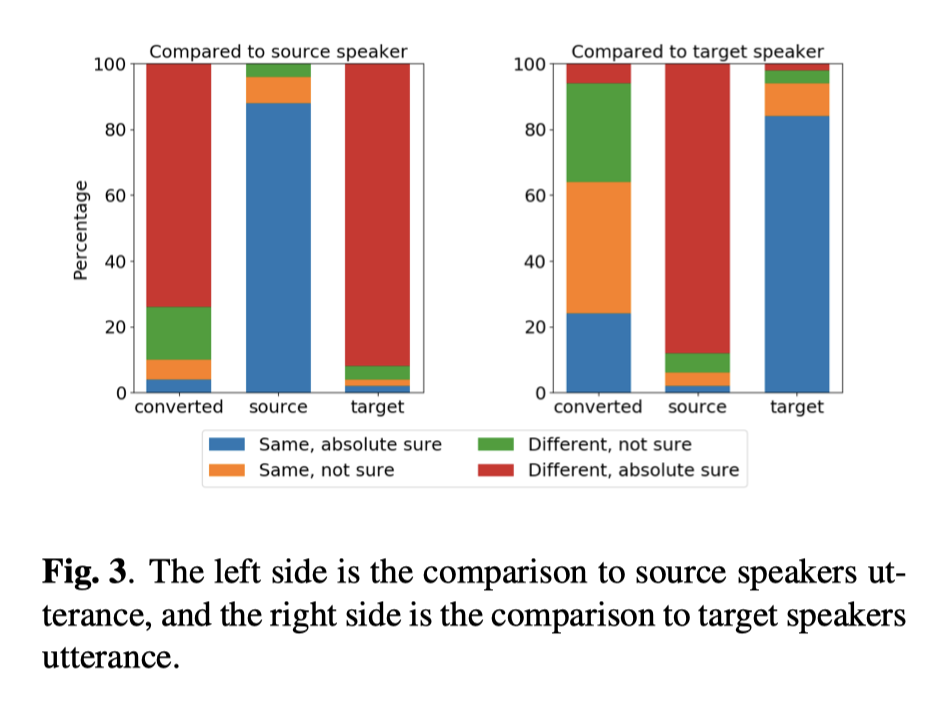
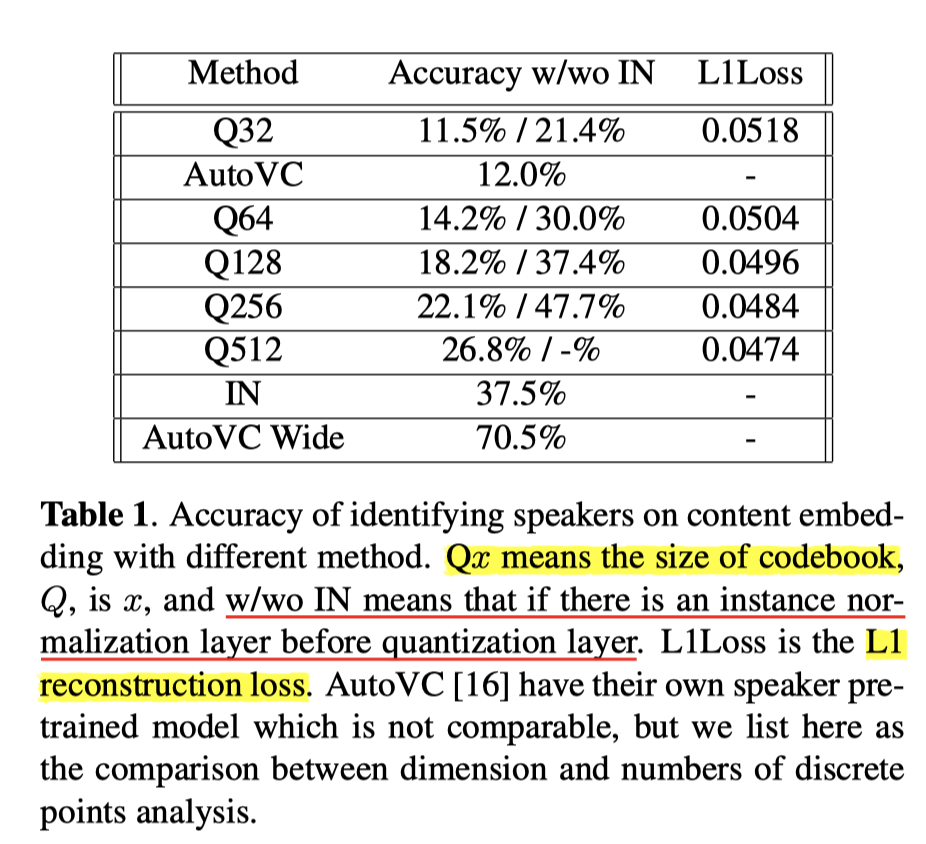
Speaker Embedding 区分度:语音片段长度120帧;CodeBook 尺寸 32;训练使用数据 20 人

疑问点:
量化部分的具体操作看不懂,说的不详细
没有代码对照

总结:
- 创新意义 > 实用意义
- 没脱离 AE 结构,还是在隐变量 特征解耦上做文章,效果不突出;
- Demo 听起来,语气语调信息损失严重
- 当作已有方法总结中的一种,不建议使用
- 开题报告
- PPT