
Diffusion Model
Diffussion Model——扩散概率模型
——适用于所有的生成类任务:TTS (☑️)、VC(❓)
——其实和VAE有点像:多层 VAE
最早见刊时间 1995-2004
论文:2015-ICML && ==2020-NIPS==
- [1] Ho, Jonathan, Ajay Jain, and Pieter Abbeel. “Denoising diffusion probabilistic models.” Advances in Neural Information Processing Systems 33 (2020): 6840-6851.
- [2] Sohl-Dickstein, Jascha, et al. “Deep unsupervised learning using nonequilibrium thermodynamics.” International Conference on Machine Learning. PMLR, 2015.
《AiShell3》
1108组会:
-
完成软著申请
-
完成 开题PPT 修改
-
完成 VC综述 论文整理
-
尚未完成 开题综述 主体部分(花了较多时间看格式处理)
-
阅读《AiShell-3》论文:值得分享一个亮点(speaker-embedding-cycle-consistence Loss)
Boild-polit 数据集在15043上有?
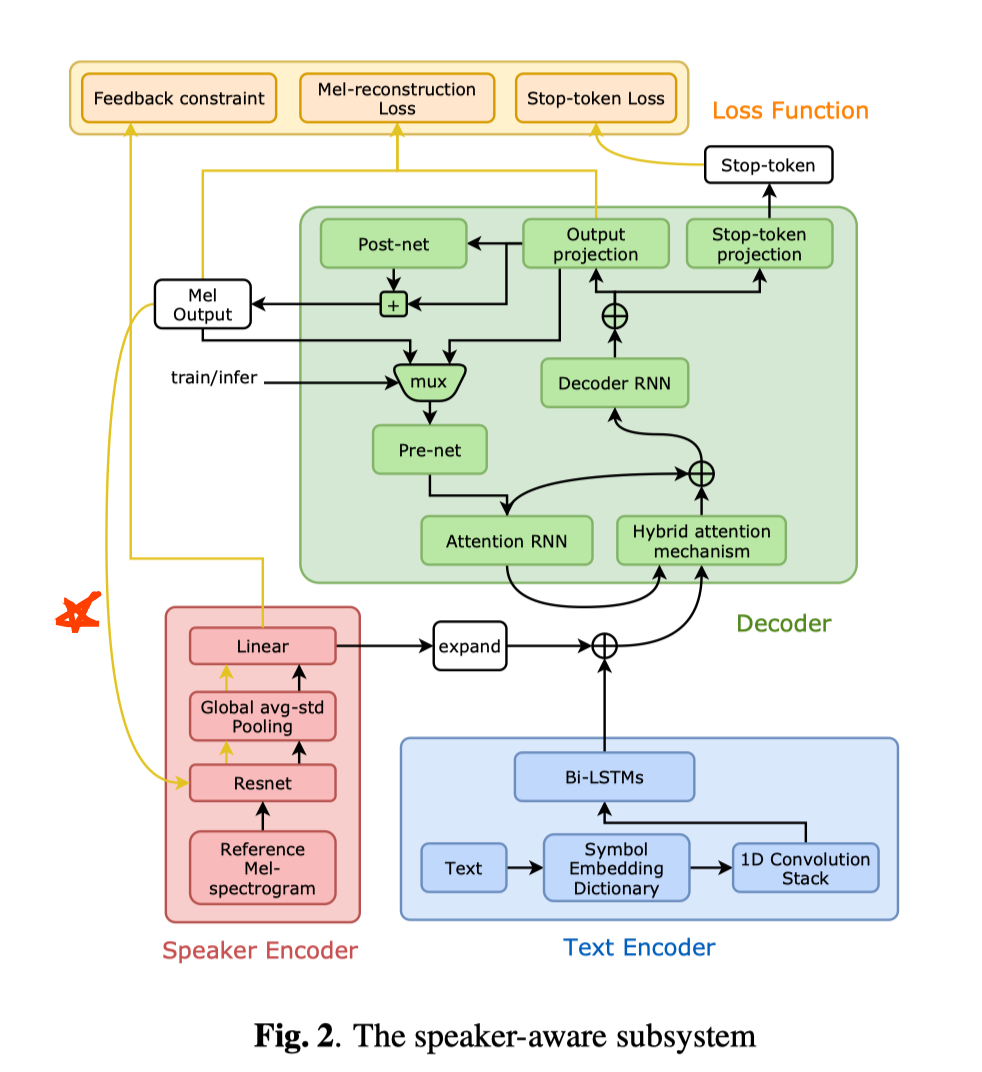
前端:Tacotron
后端:MelGAN
🌟特点:在多说话人合成任务上,为了进一步增加相似度,提出了“speaker identity feedback constraint”
公式上体现:
部分,先预训练,然后在训练 Tacotron 的时候参数不再参与训练 Frozen

另一些亮点:
Tacotron2 中,对长序列语音的合成,表现乏力;
通常改进方法是:从 hybrid-attention mechanism 改进为 purely location-based attention mechanisms ,即 Attention 机制的改进
但是这么弄,会使得 长句子的 韵律表现很差
本文转用 data augmentation 数据增强 来处理长句子合成问题
扩充后的数据用于微调收敛于原始数据集的TTS模型。
在语音合成任务中,之前较少看见 VAD 操作,一般在识别任务上用的比较多;
- 本文在数据预处理上,用 基于能量谱的 VAD 来对训练集 语音开始部分的静音帧进行去除
- 帮助加速后续的 优化对齐环节
🌟备注:
- 在公司里 && VCC2020中,很多队伍提到,用 24k 的生成效果比 16k 提升显著,本文是用16k,之后可从这个点做稍微提升
1103——WaveNet & 机器学习 考点小结
《ONE-SHOT VOICE CONVERSION BY VECTOR QUANTIZATION》
1018组会
VQVC 简析
- 《ONE-SHOT VOICE CONVERSION BY VECTOR QUANTIZATION》
- https://ericwudayi.github.io/VQVC-DEMO/

- 《VQVC+: One-Shot Voice Conversion by Vector Quantization and U-Net architecture》

《EMOTIONAL VOICE CONVERSION USING MULTITASK LEARNING WITH TEXT-TO-SPEECH》
0920-论文总结

2020.09.20
